
前回、PoWを入れたブロックチェーンの簡易モデルを作成しました。

今回はそれを使って、difficulty(先頭の0の個数)とattempts(ナンスの生成回数)の関係を調べていきたいと思います。
使用するコード
使用するコードは以下のものです。
import hashlib
import time
class Block:
def __init__(self, data, previous_hash, nonce, hash, timestamp):
self.data = data
self.previous_hash = previous_hash
self.nonce = nonce
self.hash = hash
self.time = timestamp
def calculate_hash(self):
content = self.data + self.previous_hash + str(self.nonce) + str(self.time)
hash = hashlib.sha256(content.encode()).hexdigest()
return hash
class Blockchain:
def __init__(self):
self.chain = []
self.difficulty = int(input("Difficulty: "))
self.max_block = int(input("Number of blocks: "))
print(f"\n--------------------\n")
self.total_attempts = 0 #合計試行回数の変数
genesis_block = self.create_genesis_block()
self.chain.append(genesis_block)
for i in range(1, self.max_block + 1):
self.add_block(f"block {i}")
def hash_block(self, data, previous_hash, nonce, timestamp):
content = data + previous_hash + str(nonce) + str(timestamp)
hash = hashlib.sha256(content.encode()).hexdigest()
return hash
def create_genesis_block(self):
genesis = self.mine_block("genesis", "0")
return Block("genesis", "0", genesis["nonce"], genesis["hash"], genesis["timestamp"])
def mine_block(self, data, previous_hash):
nonce = 0
attempts = 0
target = '0' * self.difficulty
start_time = time.time()
timestamp = time.time()
while True:
attempts += 1
self.total_attempts += 1 #合計試行回数をインクリメント
block_hash = self.hash_block(data, previous_hash, nonce, timestamp)
if block_hash.startswith(target):
break
nonce += 1
end_time = time.time()
elapsed_time = end_time - start_time
result = {
"nonce": nonce,
"hash": block_hash,
"timestamp": timestamp,
"elapsed_time": elapsed_time,
"attempts": attempts
}
return result
def add_block(self, data):
previous_hash = self.chain[-1].hash
mine_result = self.mine_block(data, previous_hash)
block_number = len(self.chain)
nonce = mine_result["nonce"]
hash = mine_result["hash"]
timestamp = mine_result["timestamp"]
elapsed_time = mine_result["elapsed_time"]
attempts = mine_result["attempts"]
new_block = Block(data, previous_hash, nonce, hash, timestamp)
self.chain.append(new_block)
print(f"[Block {block_number} mined]\ndata: {data}\nnonce: {nonce}\nhash: {hash}\ntimestamp: {time.ctime(timestamp)}\ntime: {elapsed_time}\nattempts: {attempts}\n")
print(f"--------------------\n")
def is_chain_valid(self):
for i in range(1, len(self.chain)):
current_block = self.chain[i]#現在のBlock
previous_block = self.chain[i-1]#一つ前のBlock
if current_block.previous_hash == previous_block.hash:
if (previous_block.time <= current_block.time) and (current_block.time <= previous_block.time + 100):
if current_block.hash == current_block.calculate_hash():
target = '0' * self.difficulty
if current_block.calculate_hash().startswith(target):
continue
else:
return False
else:
return False
else:
return False
else:
return False
return True
bc = Blockchain()
print("total attempts:", bc.total_attempts)
print("initial chain valid?:", bc.is_chain_valid())ハッシュ値の最初に並ぶ0の個数が多いほど難しいので、それをdifficultyとしてinputします。
また、生成するブロックの個数もinputで入力します。
そうするとPoWを使ってブロックが作成されて、結果が表示されます。
difficultyが5なら、hash: 0000081857826e8f8c5e⋯という感じです。
詳しくは前回の記事をご覧ください。
今回見るのは、最後のtotal attempts: 〇〇の部分です。
仮説
attemptsの回数は、difficultyに対して指数関数的に増加する。
SHA-256は2進数に基づいているので、2のn乗で増えていくのではないか。
検証
具体的な方法
number of blocks を100で固定、difficultyを1,2,3,4,5に変えて、それぞれ五回ずつ試行します。
その100ブロックの生成にかかったトータルのナンス試行回数を記録していきます。
それぞれ実行すると、以下のような画面になります。
difficultyが4のときは割と一瞬ですが、それが5になると明らかに遅くなるのがわかります↓。
実行結果
これをそれぞれ5回ずつ試行した結果は以下のようになりました。
| 1回目 | 2回目 | 3回目 | 4回目 | 5回目 | 合計 | 平均 | |
| difficulty: 1 | 1429 | 1653 | 1345 | 1649 | 1933 | 8009 | 1601.8 |
| difficulty: 2 | 19793 | 25012 | 28280 | 26274 | 24055 | 123414 | 24682.8 |
| difficulty: 3 | 454264 | 392845 | 436734 | 405510 | 387373 | 2076726 | 415345.2 |
| difficulty: 4 | 7489576 | 5879442 | 6768334 | 6350231 | 6003080 | 32490663 | 6498132.6 |
| difficulty: 5 | 116463528 | 116373275 | 110700796 | 104932554 | 105451373 | 553921526 | 110784305.2 |
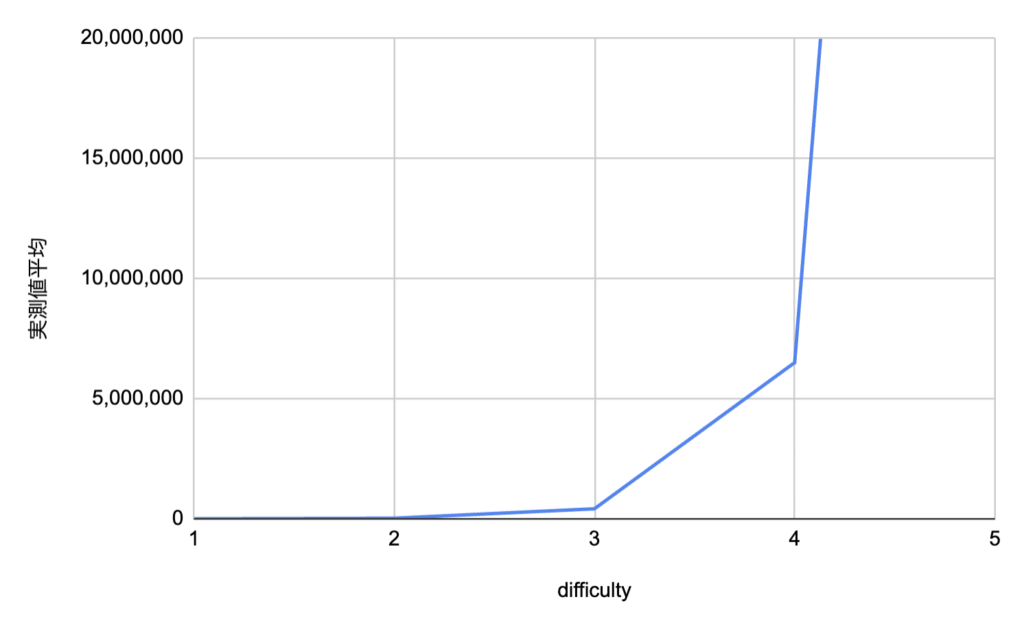
このうち、平均のナンス試行回数のみを見てみます。
| difficulty | 平均 |
| difficulty: 1 | 1601.8 |
| difficulty: 2 | 24682.8 |
| difficulty: 3 | 415345.2 |
| difficulty: 4 | 6498132.6 |
| difficulty: 5 | 110784305.2 |
考察
上の結果を見ると、difficultyが1増えるごとに、試行回数が約16倍になっていることがわかります。
difficulty1のときの値が約1600であることを考えると、
1のとき100*16^1
2のとき100*16^2
3のとき100*16^3
4のとき100*16^4
5のとき100*16^5
に近い値が出ていることがわかります。
これらの値と、今回測定した値を比較してみます
| difficulty | 予想 | 実測値 | 理論値 | 差 | 相対誤差(%) |
| difficulty: 1 | 100*16^1 | 1601.8 | 1600 | 1.8 | 0.1125 |
| difficulty: 2 | 100*16^2 | 24682.8 | 25600 | -917.2 | 3.5828125 |
| difficulty: 3 | 100*16^3 | 415345.2 | 409600 | 5745.2 | 1.402636719 |
| difficulty: 4 | 100*16^4 | 6498132.6 | 6553600 | -55467.4 | 0.8463653564 |
| difficulty: 5 | 100*16^5 | 110784305.2 | 104857600 | 5926705.2 | 5.65214653 |
誤差は一番多いdifficulty5のときでも6%に収まっています。
と、それぞれ5回しか試行していないにも関わらず、かなりの精度の値が出てきました。
こうなる理由
このような結果になる理由として、SHA-256の仕組みと、今回のPoWの条件が関係しています。
今回用いたSHA-256は16進数で表記されています。
0,1,2,3,4,5,6,7,8,9,a,b,c,d,e,fの16種類が用いられます。
ですから、文字は16通りからランダムに選ばれるといえるでしょう。
difficultyをnに設定するとき、それは、ハッシュ値の先頭に0がn個並ぶということです。
一桁目が0になる確率は、1/16です。
よって、先頭n桁が0になる確率は、(1/16)^nということになります。
0を1個ふやすごとに、確率が1/16倍になるので、計算の手間は16倍になるのです。
今回の実験では、ブロックの作成個数が100だったので、
1ブロックあたりの期待試行回数:16^difficulty
ブロック数:100
なので、理論的な総試行回数は:
100 × 16^difficultyとなります。
したがって、logスケールで見れば、ほぼ一直線に並んでいることが確認できます。
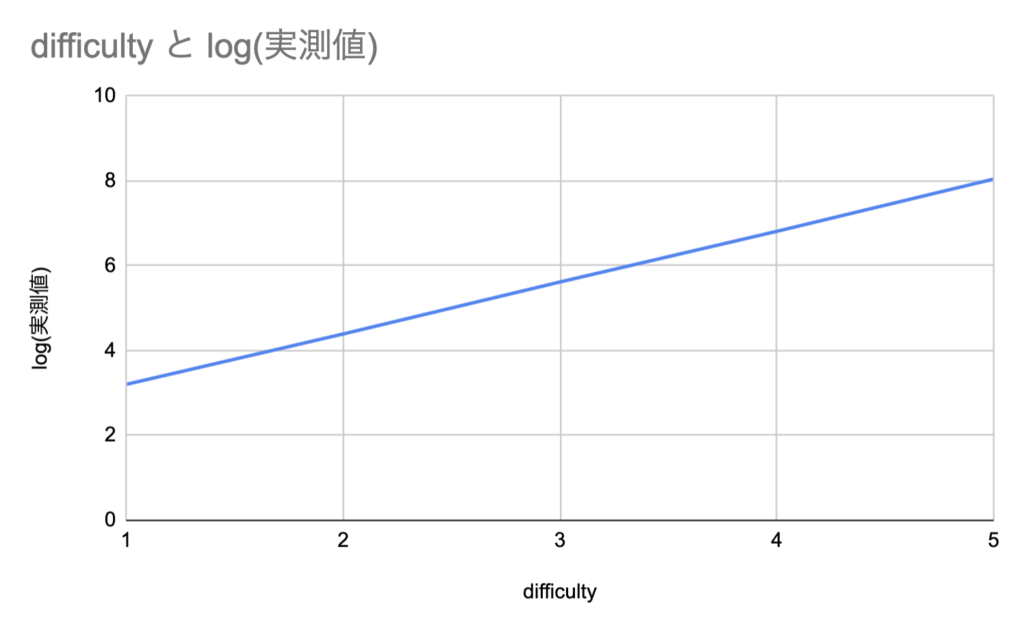
対数スケールでは指数関数的な増加は直線としてグラフに現れます。
このグラフからわかるのは、attemptsがdifficultyに対して指数関数的に増加しているということです。
実測値がこの値に非常に近いのは、PoW が単純な確率試行の繰り返しであることと、
ブロック数を100とったことで十分に平均化できたためです。
なぜ多少の誤差が出るのか
誤差が生じる理由は以下の通りです。
PoWは本質的に確率過程
試行回数が大きくなるほど分散も大きくなる
特にdifficultyが高くなるにつれて、一部のブロックで極端に早く成功するまたは逆に非常に遅くなるブロックが出るということが発生します。
つまり値の揺らぎが出るのです。
それでも difficulty = 5 で誤差が6%未満に収まっているのは、
100ブロック×5試行というサンプル数が十分に大きいためだと考えられます。
足りないかと思っていましたが、以外にもいい結果になりました。
仮説では、2のn乗で増えていくのではないかと異なる予想していました。無意識にbitで考えていた勘違いでした。
SHA-256は内部的には2進数で動作していますが、今回difficultyの判定に使っているのは16進表記の文字列です。
もし先頭のn個のビットが0かという基準で判定していた場合、2^nになりますが、今回は先頭 n hex digitが0かなので、
16^n = (2^4)^n = 2^(4n)という増加になります。
この違いは、difficultyの定義の仕方の違いによるものです。
まとめ
今回の検証により、PoW における attempts は確率試行の結果であり、difficultyを 1 増やすごとに期待試行回数は約16倍になることを確認することができました。
実測値は理論値と高い精度で一致し、自作モデルでも PoW の本質的性質が確認できました。
今後の展望として、nonceをランダムにしたり、生成時間を調べたり、チェーンが長い方を採用する仕組みなどを入れたりして、パワーアップさせていきたいと思います。
ご覧いただきありがとうございました。